4.1.3 Cassandra 持久化实体映射
在第 3 章中,您在实体类型(Taco、Ingredient、Order 等等)上使用 JPA 规范提供的注解。这些注解将实体类型映射到要持久化的关系型数据库表上。但这些注解在使用 Cassandra 进行持久化时不起作用,Spring Data Cassandra 提供了一组自己的注解,用于完成类似的映射功能。
让我们从最简单的 Ingredient 类开始,这个新的 Ingredient 类如下所示:
package tacos;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.RequiredArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor(access=AccessLevel.PRIVATE, force=true)
@Table("ingredients")
public class Ingredient {
@PrimaryKey
private String id;
private String name;
private Type type;
public static enum Type {
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}
Ingredient 类似乎否定了我所说的只需替换一些注解。在这里不用 JPA 持久化那样的 @Entity 注解,而是用 @Table 注解,以指示应该将 Ingredient 持久化到一张名为 ingredients 的表中。不是用 @id 注解在 id 属性上,而是用 @PrimaryKey 注解。到目前为止,您似乎只替换了很少的几个注解。
但别让 Ingredient 类欺骗了您。Ingredient 类是最简单的实体类型。当您处理 Taco 类时,事情会变得复杂。
程序清单 4.1 为 Taco 类添加 Cassandra 持久化注解
package tacos;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.UUID;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Size;
import org.springframework.data.cassandra.core.cql.Ordering;
import org.springframework.data.cassandra.core.cql.PrimaryKeyType;
import org.springframework.data.cassandra.core.mapping.Column;
import org.springframework.data.cassandra.core.mapping.PrimaryKeyColumn;
import org.springframework.data.cassandra.core.mapping.Table;
import com.datastax.oss.driver.api.core.uuid.Uuids;
import lombok.Data;
@Data
@Table("tacos")
public class Taco {
@PrimaryKeyColumn(type=PrimaryKeyType.PARTITIONED)
private UUID id = Uuids.timeBased();
@NotNull
@Size(min = 5, message = "Name must be at least 5 characters long")
private String name;
@PrimaryKeyColumn(type=PrimaryKeyType.CLUSTERED,
ordering=Ordering.DESCENDING)
private Date createdAt = new Date();
@Size(min=1, message="You must choose at least 1 ingredient")
@Column("ingredients")
private List<IngredientUDT> ingredients = new ArrayList<>();
public void addIngredient(Ingredient ingredient) {
this.ingredients.add(TacoUDRUtils.toIngredientUDT(ingredient));
}
}
正如您所看到的,映射 Taco 类的内容更为复杂。与 Ingredient 一样, @Table 注解用于将 TACO 类标识为使用 tacos 表进行保存。但这是唯一与 Ingredient 类相似的地方。
id 属性仍然是主键,但它只是两个主键列中的一个。更具体地说,id 属性使用注解 @PrimaryKeyColumn,且设置类型为 PrimaryKeyType.PARTITIONED。 这样设置指定了 id 属性作为分区键,用于确定每行 taco 应该将数据写入哪个 Cassandra 分区。
您还注意到 id 属性现在是 UUID,而不是 Long 类型。尽管不是强制的,但 ID 值属性通常为 UUID 类型。此外,新 Taco 对象的 UUID 是基于时间的 UUID 。(但从数据库读取已有的 Taco 时,可能会覆盖该值)。
再往下一点,您会看到 createdAt 属性被映射为主键列的另一个属性。本例中,设置了 @PrimaryKeyColumn 的 type 属性为 PrimaryKeyType.CLUSTERED,它将 createdAt 属性指定为聚类键。如前所述,聚类键用于确定分区中的行数据的顺序。更具体地说,排序设置为降序。因此,在给定的分区中,较新行首先出现在 tacos 表中。
最后,ingredients 属性现在是一个 IngredientUDT 对象的列表。正如您所记得的,Cassandra 表是非规范化的,可能包含从其他表复制的数据。虽然 ingredients 表将作为所有可用 Ingredient 的记录表,但每个 taco 的 Ingredient 会在 ingredients 中重复出现。这不仅仅是简单地引用 ingredients 表中的一行或多行,而是在 ingredients 属性中包含完整数据。
但为什么要引入一个新的 IngredientUDT 类呢?为什么不重用 Ingredient 类呢?简单地说,包含数据集合的列,例如 ingredients 列,必须是基本类型(整数、字符串等)或用户自定义类型的集合。
在 Cassandra 中,用户自定义的类型和基本类型相比,允许您声明更丰富的表和列属性。通常,它们类似关系型数据库的外键。但与外键不同,外键只保存在另一个表的行数据中。但用户自定义类型的列,实际上可能携带从另一个表的行中复制的数据。对于 tacos 表中的 ingredients 列,它将包含所有 ingredients 的数据。
不能将 Ingredient 类用作自定义的类型,因为 @Table 注解已经将其映射为 Cassandra 中持久化的一个实体。因此,您必须创建一个新类,来定义如何在 taco 表上的 ingredients 列。IngredientUDT 类用于达到此目的(其中 “UDT” 是 user defined type 的缩写,表示用户自定义类型):
package tacos;
import org.springframework.data.cassandra.core.mapping.UserDefinedType;
import lombok.AccessLevel;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.RequiredArgsConstructor;
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
@UserDefinedType("ingredient")
public class IngredientUDT {
private final String name;
private final Ingredient.Type type;
}
尽管 IngredientUDT 看起来很像 Ingredient,但它的映射简单的多。它用 @UserDefinedType 注解,以将其标识为用户自定义的类型。除此之外,它就是一个具有一些属性的简单类。
您还将注意到,IngredientUDT 类并不包含 id 属性。尽管它可能包含从 Ingredient 复制来的 id 属性的副本。事实上,用户自定义的类型可能包含您需要的任何属性,它不需要与任何表定义进行一对一的映射。
我意识到您现在可能没有一个清晰的完整视图,来理解用户自定义类型中的数据是如何关联,并持久化到库中的。图 4.1 显示了整个 Taco Cloud 的数据模型,包括用户自定义的类型。
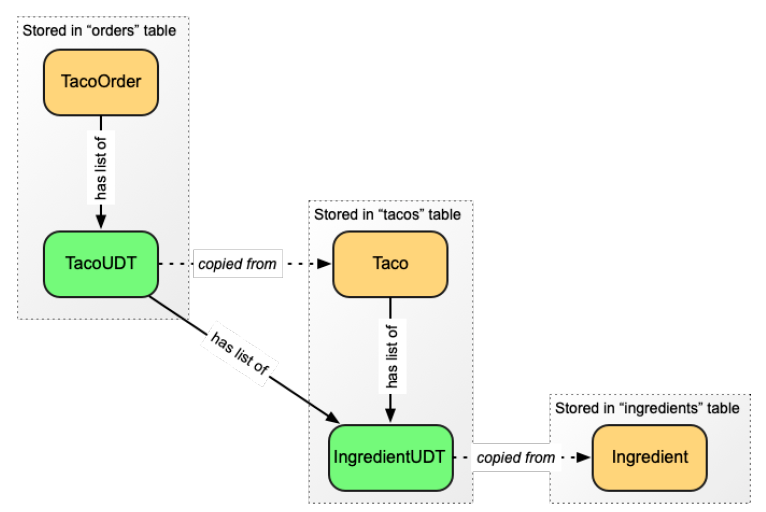 图 12.1 不用外链和关联, Cassandra 是反范式的, 用户自定义类型包含其他表中的数据复本。
图 12.1 不用外链和关联, Cassandra 是反范式的, 用户自定义类型包含其他表中的数据复本。
具体到您刚刚创建的用户自定义类型,请注意 Taco 有一个 IngredientUDT,它保存从 Ingredient 对象复制的数据。当一个 Taco 被持久化的时候,是 Taco 对象和其中的 IngredientUDT 列表被保存到 tacos 表中。IngredientUDT 的列表数据全部保存到 ingredients 列中。
另一种方法可以帮助您理解用户自定义类型的使用,就是查询 tacos 表在数据库中的数据。使用 CQL 和 Cassandra 附带的 cqlsh 工具可以看到以下结果:
cqlsh:tacocloud> select id, name, createdAt, ingredients from tacos;
id | name | createdat | ingredients
---------+-----------+-----------+----------------------------------------
827390...| Carnivore | 2018-04...| [{name: 'Flour Tortilla', type: 'WRAP'},
{name: 'Carnitas', type: 'PROTEIN'},
{name: 'Sour Cream', type: 'SAUCE'},
{name: 'Salsa', type: 'SAUCE'},
{name: 'Cheddar', type: 'CHEESE'}]
(1 rows)
如您所见,id、name 和 createdAt 列包含简单值。它们与您熟悉的关系型数据的查询没有太大的不同。但是 ingredients 有点不同。因为这个列定义为包含用户自定义类型的集合(由 IngredientUDT 定义),它的值显示为一个 JSON 数组,其中包含 JSON 对象。
您可能注意到 图 4.1 中的其他用户自定义类型。您需要继续将其他实体映射到 Cassandra 表。还需要加一些注解,包括 TacoOrder 类。下一个清单展示了为 Cassandra 持久化进行注解的 TacoOrder 类。
程序清单 4.2 映射 TacoOrder 类到 Cassandra 数据库的 tacoorders 表
package tacos;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.UUID;
import javax.validation.constraints.Digits;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.Pattern;
import org.hibernate.validator.constraints.CreditCardNumber;
import org.springframework.data.cassandra.core.mapping.Column;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
import com.datastax.oss.driver.api.core.uuid.Uuids;
import lombok.Data;
@Data
@Table("orders")
public class TacoOrder implements Serializable {
private static final long serialVersionUID = 1L;
@PrimaryKey
private UUID id = Uuids.timeBased();
private Date placedAt = new Date();
// delivery and credit card properties omitted for brevity's sake
@Column("tacos")
private List<TacoUDT> tacos = new ArrayList<>();
public void addTaco(TacoUDT taco) {
this.tacos.add(taco);
}
}
程序清单 4.2 故意省略了 TacoOrder 类的一些属性,这些属性本身并不适用对 Cassandra 数据建模的探讨。剩下的一些属性和映射,类似于 Taco 上的注解。@Table 用于将 TacoOrder 映射到 tacoorders 表。在里,由于您不关心排序,id 属性只需用 @PrimaryKey 注解,指定它既是一个分区键,又是一个具有默认顺序的聚类键。
tacos 属性很有趣,因为它是一个 List<TackUDT>, 而不是一个 Taco 列表。这里 TacoOrder 和 Taco/TacoUDT 之间的关系,类似于 Taco 和 Ingredient/IngredientUDT 的关系。也就是说,不是通过外键将表中的多行数据链接起来,而是在 TacoOrder 表中包含所有相关的 taco 数据,以优化表的读取速度。
至于 TacoUDT 类,它与 IngredientUDT 类非常相似,不过它包含引用其他用户定义类型的集合:
package tacos;
import java.util.List;
import org.springframework.data.cassandra.core.mapping.UserDefinedType;
import lombok.Data;
@Data
@UserDefinedType("taco")
public class TacoUDT {
private final String name;
private final List<IngredientUDT> ingredients;
}
尽管,重用在第 3 章中创建的实体类,或者把一些 JPA 注解换成 Cassandra 注解,应该更方便,但 Cassandra 持久化的本质特性决定了不能这样做。它要求您重新思考数据的建模方式。现在实体都已经映射了,可以编写 Repository 了。